이 부분을 읽기 전에 아래 링크인 판다스 관련 내용을 참고합시다!
Python_[anaconda] 데이터 관리(3)
1.오라클 접속 👆기초작업 *오라클 데이터 베이스에 접속하기_ cx_Oracle이용 Python 에서 Oracle Database 에 접속해 조회, 등록등 작업하려면 파이썬 라이브러리(DB접속 드라이버)가 필요! 아나콘다 promp
oort2.tistory.com
빅데이터를 다룰때 제일 힘든건
첫째도 자료 모으기. 둘째도 자료모으기 입니다.
크롤링하는 것도 나중에 배운다는데 배우고 나면 정리하겠습니다.
#오늘 자료: 행정안전부발 정책자료-> 연령별인구현환(2022년도)
1. data를 참고해서 필요한 부분을 추출해 그래프로 출력.
| import pandas as pd import matplotlib.pyplot as plt #---(1) df=pd.read_csv("data/age.csv", encoding="cp949",thousands=",",index_col=0) # ---(2) |
1. 임포트 및 데이터 불러오기
1)pandas( 표 형태의 데이터를 처리하기 위한 모듈)와 mapplotlib(데이터를 시각화 할 수 있는 모듈)을 임포트 합니다.
2)thousands="," : 숫자에 세자리마다 , 를 제거함. 숫자만읽기.
index_col=0 : 0번컬럼을 인덱스로 설정.= > 행정구역 컬럼이 인덱스로 설정됨
| name ="역삼" # ---(1) df2=df[df.index.str.contains(name)] # ---(2) df2 #지정 지역 데이터 |
2.원하는 값 인덱스 추출하기
1) 역삼이라는 이름이 들어간 지역을 찾습니다.
2)df.index의 인덱스를 str형으로 바꿔서 '역삼'이 있는지 찾아 df2로 만들기
3)총 2건 출력 (out)
2022년11월_계_총인구수 ... 2022년11월_계_100세 이상
행정구역 ...
서울특별시 강남구 역삼1동(1168064000) 34604 ... 2
서울특별시 강남구 역삼2동(1168065000) 36985 ... 2
| col_name=['총인구수','연령구간인구수'] # ---(1) for i in range(0,101): col_name.append(str(i)+'세') # ---(2) col_name # ---(3) df2.columns=col_name # ---(4) del df2['총인구수'],df2['연령구간인구수'] # ---(5) |
3.출력할 부분 컬럼 수정하기
1)col_name에 총인구수, 연령구간인구수 라는 값을 넣기
2) i가 0부터 100까지 돌 때(df2의 나이 컬럼 갯수만큼) : col_name의 값 뒤에 'i세' 라는 값을 넣기.
3)col_name (out) => df2의 컬럼의 값은 각각 [ 2022년11월_계_총인구수, ... ,2022년11월_계_100세 이상]으로 102개의 열이었음.
['총인구수', '연령구간인구수', '0세', '1세', '2세', ... '99세', '100세']
4)df2.columns 값에 방금 만든 값을 집어 넣기.
5) 총인구수와 연령구간 인구수의 값을 삭제하기 =>이렇게 해야지 그래프가 예쁘게 나옴.
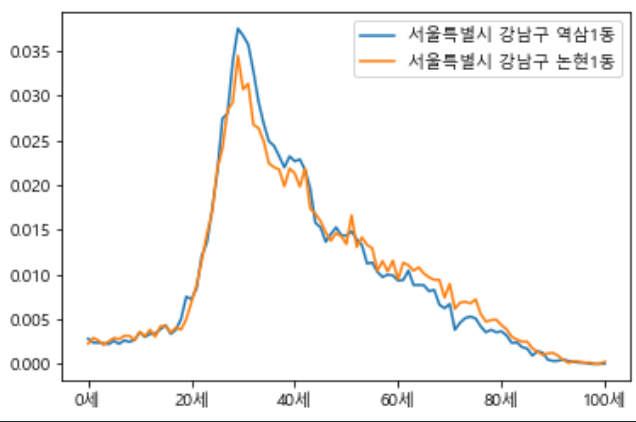
| for i in range(0,len(df2)): names=list(df2.index) # ---(1) names[i] = names[i][0:names[i].find('(')] # ---(2) names[i] # ---(3) df2.index = names df2.index df2.T.plot() # ---(4) plt.rc('font', family='Malgun Gothic') # ---(5) plt.legend() # ---(6) |
4.범례에 들어갈 이름 수정 및 출력하기
1) i가 0부터 df2-1만큼 돌 때 (여러개의 값을 출력할 수도 있기에 df2가 들어간 길이 len(df2)로 출력):
리스트 타입인 df2.index를 차례대로 names 값에다 넣는다.
2) names[i]번항의 열을 전체 출력하되 '(' 앞까지 출력한다. => 서울특별시 강남구 역삼1동(111100000)를(out)
3)서울특별시 강남구 역삼1동
서울특별시 강남구 역삼2동
4)df2를 plot 형태로 출력하되 대치하여 출력한다.
5)plot의 폰트는 맑은고딕으로 한다.(이래야지 한글이 안깨짐
6)plot에 범례를 설정한다. (out)

2. 가장 비슷한 지역 한개만 그래프로 출력
| import pandas as pd import matplotlib.pyplot as plt df=pd.read_csv("data/age.csv", encoding="cp949",thousands=",",index_col=0) #--(1) col_name=['총인구수','연령구간인구수'] for i in range(0,101): col_name.append(str(i)+'세') col_name df2.columns=col_name del df2['총인구수'],df2['연령구간인구수'] #--(2) |
1. 임포트 및 데이터 불러오기 (상동)
2.출력할 부분 컬럼 수정하기 (상동)
| df.count() # ---(1) df.fillna(0,inplace=True) # ---(2) df.count() # ---(3) name ="역삼" a=df.index.str.contains(name) # ---(+) a df2=df[df.index.str.contains(name)] df2 # ---(4) names=list(df2.index) names[0] = names[0][0:names[0].find('(')] names[0] df2.index = names ---(5) df2 |
3.결측값 해결 및 원하는 값 인덱스 찾기
1)컬럼의 결측값(null)이 아닌 데이터의 건수 (out) 3854
2) 결측값을 0으로 치환 #fillna: 결측값을 다른 값으로 치환
3)(out) 3870 => 치환을 해줘야지 비교가 더 정교해짐
4)원하는 값 인덱스 추출하기 (상동)
5)범례에 들어갈 이름 수정하기(상동)
+) a에 해당 numpy.ndarray을 넣기
b=list(map(lambda x : not x, a)) # ---(1) df3=df[b] # ---(2) mn=1 # ---(3) df4=df3.T # ---(4) df4 |
4.기준값 외 전체값 만들기
1)name not in row[0] 을 찾아 리스트로 만들고 그 값을 b에 넣는다.
2)df3:에 a값을 제외한 다른 데이터만 전부 저장한다.
3)mn에 최솟값으로 1을 넣는다. 나눠서 비교할거라 1을 넣어야 한다.
4)df4에 df3을 전치한 값을 넣는다
| for label, content in df3.T.items(): # ---(1) s = sum((content - df2.iloc[0])**2) # ---(2) if s<mn; mn = s; result=content result.name= result.name[:result.name.find('(')] df2.T.plot() result.plot() plt.legend() # ---(4) |
5. 값 비교 및 출력
1) label(행정동명), content(행정동 데이터) 0~100까지 돌릴 때:
2) 지정된 지역(역삼동)과 현재 데이터(전체값을 순차적으로 돌릴때)의 오차에 대한 제곱의 합을 s에 넣는다.
3)만약 s값이 최소값보다 작다면;
mn에 s를 넣고; result에 contend(행정동 데이터)를 넣고,
names[i]번항의 열을 전체 출력하되 '(' 앞까지 출력한다.
4)지정된 데이터와, 최소값으로 찾은 데이터를 범례와 함께 출력한다(out)
'STUDY > Python' 카테고리의 다른 글
| Python[빅데이터] pandas 활용(3) (0) | 2023.02.24 |
|---|---|
| Python[빅데이터] pandas 활용(2) (0) | 2023.02.23 |
| Python_[anaconda] 데이터 관리(3) (0) | 2023.02.20 |
| Python_[anaconda] 데이터 관리(2) (0) | 2023.02.20 |
| Python_[anaconda] 데이터 관리(1) (0) | 2023.02.19 |